
Storyboard synthesis plays a crucial role in visual storytelling, aiming to generate coherent shot sequences that visually narrate cinematic events with consistent characters, scenes, and transitions. However, existing approaches are mostly adapted from text-to-image diffusion models, which struggle to maintain long-range temporal coherence, consistent character identities, and narrative flow across multiple shots.
In this paper, we introduce DreamShot, a video generative model based storyboard framework that fully exploits powerful video diffusion priors for controllable multi-shot synthesis. DreamShot supports both Text-to-Shot and Reference-to-Shot generation, as well as story continuation conditioned on previous frames, enabling flexible and context-aware storyboard generation. By leveraging the spatial-temporal consistency inherent in video generative models, DreamShot produces visually and semantically coherent sequences with improved narrative fidelity and character continuity. Furthermore, DreamShot incorporates a multi-reference role conditioning module that accepts multiple character reference images and enforces identity alignment via a Role-Attention Consistency Loss, explicitly constraining attention between reference and generated roles.
Extensive experiments demonstrate that DreamShot achieves superior scene coherence, role consistency, and generation efficiency compared to state-of-the-art text-to-image storyboard models, establishing a new direction toward controllable video model-driven visual storytelling.
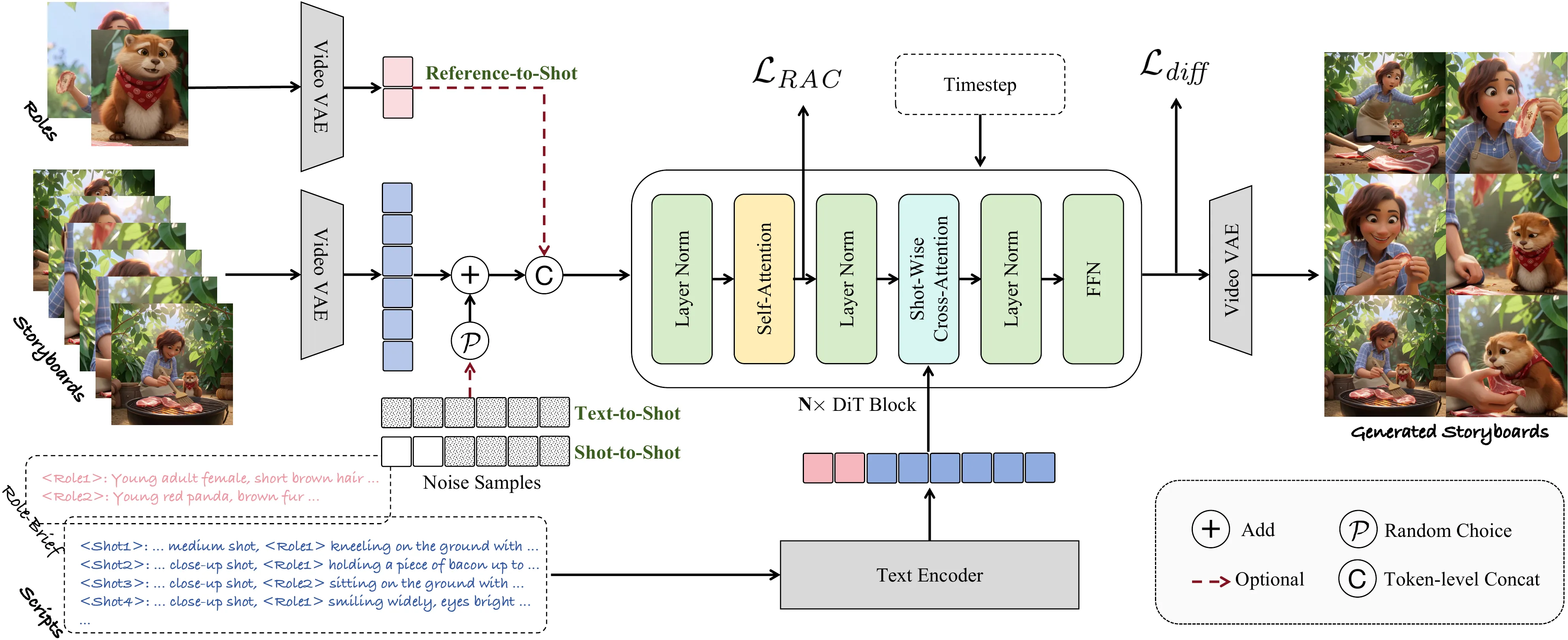
The overall framework of DreamShot consists of a Video-VAE (e.g., Wan-VAE) and a DiT module. Our model supports three generation modes: Reference-to-Shot, Text-to-Shot, and Shot-to-Shot. During inference, both the character reference image and the storyboard reference shots are introduced in a clear, noise-free form. Each shot interacts with its corresponding textual script through shotwise cross-attention, enabling the generation of diverse storyboard shots that maintain consistent character identity and scene coherence.
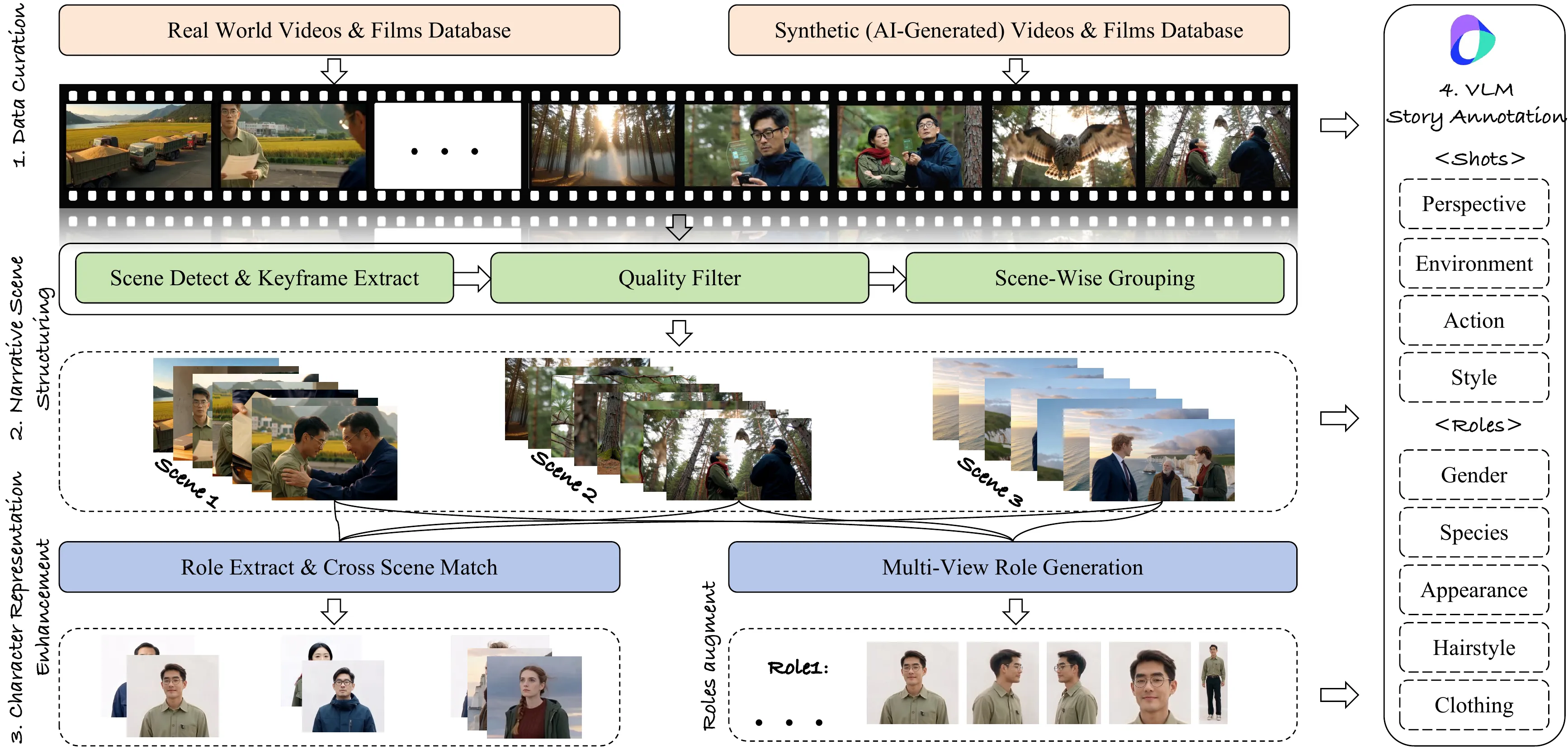
Overview of the data construction pipeline. The process consists of four main stages: data source selection, keyframe extraction and scene-wise grouping, role extraction and augmentation, and story annotation. Rigorous quality control is applied at each stage to ensure the consistency and reliability of the dataset.

Qualitative comparisons with existing methods. (a) Reference-to-Shot generation. Compared with other methods, our approach adapts well to shot transitions while maintaining consistent environmental layout across scenes. (b) Text-to-Shot generation. Our results reflect better cinematic storytelling rather than portrait-like compositions, while achieving superior character consistency across shots.

Qualitative results between our method and UNO in VistoryBench. Our method demonstrates superior character consistency, as reflected in the first storyboard group where fine-grained details such as the girl’s hair accessories are better preserved. In the case of long storyboard sequences, shown in the second group, our approach also exhibits strong generalization ability. The entire sequence maintains a more coherent style and scene layout compared with UNO.
@article{huang_dreamshot,
title = {DreamShot: Personalized Storyboard Synthesis with Video Diffusion Prior},
author = {Junjia Huang, Binbin Yang, Pengxiang Yan, Jiyang Liu, Bin Xia, Zhao Wang, Yitong Wang, Liang Lin, Guanbin Li},
journal = {arXiv preprint arXiv:2604.17195},
year = {2026}
}